
Nate Silver, the former New York Times election modeler who called 49 states correctly in the 2008 presidential election, somehow improved on that record in 2012 by correctly predicting the electoral college winner in all 50 states. And what made the accomplishment even more impressive was how close the elections were in several states. In North Carolina, for example, Mitt Romney won by barely 2 percent. But it was the razor-thin Obama win in Florida, which many polls had suggested would go to Romney, that allowed Silver to claim prediction perfection in 2012.
But what if it turned out that Silver’s Florida prediction was due to a last-second poll released by a company whose results methods are now being called into question by a bipartisan group of polling experts? What if Silver’s perfect 2012 prediction was caused entirely by a single poll from a company which may well have cooked its data to get a certain result?
To understand how a single poll from a single questionable polling firm likely sealed the fate of Nate Silver’s 2012 model, and to understand the implications of Silver’s model hinging on a potentially bogus last-second Florida poll,we need to first look at how that polling firm operates.
Public Policy Polling’s 2012 Reputation
The polling company in question, Public Policy Polling (PPP) of Raleigh, North Carolina, made something of a name for itself following the 2012 elections. Tom Jensen, the company’s founder, regularly thumps his chest about also having accurate poll results in every state in 2012.
“While Nate Silver got a lot of attention for predicting the election through poll aggregation and statistics, Public Policy Polling nailed every state through first-hand polling,” the website Business Insider wrote last November.
“It feels great,” Jensen told Business Insider. “It vindicates that we are making the right assumptions about the electorate.”
Immediately following the 2012 election, Jensen also viciously attacked critics of his methodology.
“These supposed polling experts on the conservative side are morons,” Jensen seethed to New York magazine.
“But Jensen conceded that the secret to PPP’s success was what boiled down to a well informed but still not entirely empirical hunch,” the article continued.
In theory, though, pollsters are not hired to make blithe predictions or hunches about the electorate. Their job is find and report what poll respondents have told them about how they plan to vote. And the distinction between those two different activities — analyzing what the electorate is telling them versus guessing about what the electorate might look like — is what separates pollsters with years of training and experience in high-level statistics from your average political junkie who has a certain gut feel about how the next election will turn out. The former, with its consistent and clearly described methods, data available for inspection, and reproducibility of results, involves something approaching science, while the latter is just guessing covered with a veneer of pseudo-scientific language.
Over the last few days, Jensen has found himself embroiled in a scandal surrounding PPP’s methodology — the very same methodology that raised the ire of PPP’s critics throughout the 2012 election season.
The Colorado Recall Non-Disclosure
First, Jensen admitted to mothballing a poll of a Colorado recall election because he didn’t think the results — which showed an anti-gun Democratic state senator being overwhelmingly recalled by her predominantly Democratic constituents — made sense. Then, the morning after the actual recall took place and the results were announced (former Colorado state senator Angela Giron was recalled in a landslide), Jensen released the previously undisclosed poll to show that he had correctly called the race.
“When we got the results back, we found that 33% of Democrats in the district supported the recall,” Jensen wrote on PPP’s blog. “That finding made me think that respondents may not have understood what they were being asked, so I decided to hold onto it.”
That move to only release the poll after-the-fact struck many as odd. It’s one thing to not release polling data that may make your clients or your favored policy positions look good — political campaigns do this all the time, which is one reason so many analysts are highly skeptical of internal polls leaked by political campaigns. But it’s another thing entirely to keep data secret only to release it after the fact and take credit for having been correct the whole time. An ex-post victory lap requires ex-ante risk-taking. Nobody trusts the guy who suddenly claims on Monday morning to have correctly predicted the precise score of Sunday night’s Super Bowl.
Even more problematic for Jensen is that he had previously testified as an expert witness in legal proceedings surrounding the Colorado recall. The plaintiffs in the case, on whose behalf Jensen testified, argued that the petition process by which the recall was initiated was too confusing and that the recalls should be invalidated as a result. The main piece of evidence used by the anti-recall foes was a poll conducted by PPP. The judge in the case characterized Jensen’s testimony as “unconvincing” and “even went so far as to give the Democrats a dressing-down for hiring a pollster in their effort to block the recalls,” the Washington Times reported.
The “voter confusion” theme Jensen cited as his reason not to release the Colorado recall poll just happened to mirror the precise narrative he offered to a Colorado court when trying to prevent the recall from ever happening in the first place. While it is unclear whether Jensen or PPP received payment in exchange for the testimony or the poll on which it was based (PPP received $200 from the Colorado Democratic Party in 2012 for unspecified services), it is abundantly clear that Jensen had a dog in the recall fight that he wanted to protect.
When paired with Jensen’s eagerness to take credit for being right only after the election results were announced, Jensen’s refusal to release the data before the election suggests his aim is not so much to publish data to inform the public, but to selectively disclose only those polls that buttress his personal political views or those of his firm’s exclusively liberal political client base. Or, perhaps more charitably, he wanted to initially hide bad news for liberals (that one of their pet candidates was about to go down in flames) and then use the polling data post-election to cast aspersions on the voters who decided it was time for two gun grabbing politicians to get real jobs. What better way to trumpet your explanation of voters’ questionable motivations than by claiming your poll totally nailed the final result? Unfortunately, neither explanation says much about Jensen’s regard for transparency.
In the political campaign world, there are generally two types of pollsters: those which work directly for political candidates, and those which do election polling paired with corporate consumer research. The firms that work for political candidates accept a credibility hit right out of the gate. They know their results will be taken less seriously given their financial connections to their candidate clients. The primarily corporate pollsters don’t have that problem, though. Those firms have an easier time appearing to be above the fray.
What makes PPP interesting in the polling world is the company’s apparent desire to have it both ways: collect the campaign cash and special interest money from political groups, while still maintaining credibility as an independent pollster who cares only about accurate, reproducible results, rather than achieving certain political goals. What the Colorado recall polling incident suggested is that PPP may have a much greater interest in promoting a certain political outcome than in publishing quality data. So much for having the best of both polling worlds.
PPP’s Sketchy Methodology
But that’s just the first the scandal. It is the second scandal, covered in depth by Nate Cohn of The New Republic, that both places PPP’s polling credibility in jeopardy and suggests that Nate Silver’s remarkable 2012 feat maybe wasn’t so remarkable at all. In his expose, entitled “There’s Something Wrong With America’s Premiere Liberal Pollster: The problem with PPP’s methodology,” Cohn took a sledgehammer to the highly irregular and statistically questionable methods used by PPP.
The thesis of Cohn’s critique is that the methodology used by Jensen and PPP is inconsistent, poorly documented, opaque to end users, and completely arbitrary.
Cohn identified a number of issues with PPP’s recent polling numbers, but the biggest issue with the company’s methodology is how it determines the demographic make-up of the electorate.
“PPP has said that their ability to divine the composition of the electorate underlies their success,” Cohn wrote. “But that composition is all over the map: In PPP’s polling, the white share of the electorate routinely swings by 4 points or more.”
As Cohn noted, those shifts are “baffling” and not apparent in polling data from other firms. PPP says it determines demographic composition by a process it calls “random deletion,” in which it throws away individual responses from certain demographic groups until those groups fall into target ranges defined by PPP. If that process sounds incredibly arbitrary and remarkably unscientific, it’s because it is.
In two PPP polls highlighted by Cohn, it is easy to see how this process can completely warp the data. In each of those two national polls, the initial raw data collected by PPP suggested an electorate that was 79 percent white. After re-weighting the data, PPP released the first poll, which showed an electorate that was 69.7 percent white. But in its second poll, which was released only a week later, the percentage of white voters jumped to over 75 percent.
“Reproducibility is at the heart of the scientific method,” Cohn wrote. “If I conduct an experiment and produce a certain result, and someone can’t do the same experiment and get the same outcome, there should be serious doubts about my finding. Incredibly, PPP’s methodology is so inconsistent that it’s not even clear it could replicate its own results with the same raw data. That should raise red flags.”
When Cohn pointedly asked Jensen whether he used demographic weightings to produce a particular final outcome, Jensen did not come even close to denying the charge.
“Maybe we’re being over cautious but we try not to make the same mistake twice,” Jensen responded. “That’s all I have to say.”
PPP’s Florida Polling in 2012
PPP’s 2012 presidential polls in Florida raise a number of questions about whether the company simply uses demographic weights to get a certain result. For example, in five polls spanning from April through September of 2012, PPP estimated on average that whites would comprise 69.8 percent of the electorate (the conventional wisdom was that the whiter the electorate, the more likely Romney was to win). In those five polls, that percentage of whites never exceeded 71 percent and never dipped below 69 percent. Over those five polls, Obama had an average lead of 3 percent.
In PPP’s final three polls, however, the white share of the electorate suddenly averaged 65.3 percent. That number never exceeded 66 percent and never dipped below 64 percent. Obama’s lead in those three polls averaged only 0.3 percent.
To put that 4.5 point drop into perspective, it is larger than the difference between the percentage of white voters in the 2004 Florida electorate (70 percent white) and the 2012 Florida electorate (67 percent white), according to statewide exit polls. In order to have any faith in the accuracy of PPP’s Florida numbers, you have to believe that for nearly six months, the Florida electorate was going to be as white as it was in 2004, until it magically and organically transformed itself with only three weeks left until election day. You must also believe that such a massive demographic shift would somehow not have changed the projected winner of the election.
Now, one could certainly argue that the first presidential debate on October 3 was responsible for Romney’s surge and Obama’s dwindling lead in Florida. But did that debate also fundamentally alter the composition of the Florida electorate? And did it alter the electorate in such a way that Romney actually became more likely to win only as whites, over 60 percent of whom supported Romney, dropped out of the likely voter pool? When I asked Jensen on Twitter last fall what caused the white vote in his Florida polls to drop from 70 percent to 65 percent overnight, he declined to respond.
How PPP’s Final Florida Poll Flipped Nate Silver’s Florida Forecast
Which takes us back to the original question: did a last-second PPP poll tip the scales of Nate Silver’s Florida model in Obama’s favor? And if it did, what are the implications? The answer to the first question, based on the timeline of events leading up to the final Silver forecast, appears to be an overwhelming “yes.”
How do we know?
Because only one poll showing Obama with a lead in Florida was released on Monday, November 5, the day before the election. That poll, which showed Obama with a 50-49 lead in Florida, was conducted by PPP and released at 12:50 a.m. on Monday, November 5. We know it mattered not only because that particular poll was the only new piece of information released that day showing Obama with a lead, but because Silver’s model gave that PPP poll a higher weight than all but two other polls included in his final forecast. The single PPP poll, which was given a weight of 1.41115, far outweighed the final Ipsos poll, which showed a 1-point Romney lead and was given a weight of 0.88991. Both polls were released on Monday, November 5.
We also know the final PPP poll mattered because Silver’s model showed Romney with an ever-so-slight lead in Florida up until roughly 10:00 p.m. the night before the election (although screen caps of the before and after are unavailable, the contemporaneous record makes clear that Silver’s model didn’t flip Florida from Romney to Obama until late that Monday night).
The final prediction produced by Silver’s model showed a 50.3 percent probability of Obama winning Florida (you’ll need to mouse-over the state to see the precise probability). In terms of the percentage of votes each candidate was expected to win, Silver’s model predicted Obama would receive 49.797 percent of the vote to Romney’s 49.775 percent — a difference of only 0.022 percent, or 2 votes cast out of 10,000. That is a margin so tiny that PPP’s final poll, given its result and its weight in Silver’s forecast, would be almost certain to have made the difference in pushing the state from Romney’s camp into Obama’s (questions posed to Silver’s Twitter account about whether PPP’s final poll was responsible for the model’s Florida flip went unanswered). Given what we know about the new information that was fed into Silver’s model on November 5 and the weights that were applied to it, Jensen’s final Florida poll for PPP appears to have been responsible for Silver getting 50 states right instead of just 49.
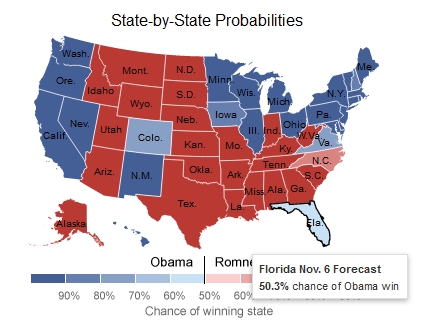
By Silver’s own admission, PPP’s unorthodox methods would have resulted in severe weighting penalties levied against the company’s polls in Silver’s model.
“We’re not exactly known for being friendly to pollsters who play fast and loose with methodology and disclosure standards,” he wrote directly to PPP’s Twitter account.
“Nor are we known for being sympathetic to private polling firms that cherry-pick which data they release,” Silver continued.
At this point, based on what we know about PPP’s methodology and how Silver would have treated the pollster’s data had he known about the firm’s irregularities, it doesn’t seem unfair to wonder what Silver’s model would’ve predicted had it been calibrated to treat PPP the same as it treated all other pollsters with shady methods. And it doesn’t seem unreasonable to ask Silver to re-run that final election eve simulation with the penalties Silver suggested factored into the model (Silver did not respond to a question on Twitter about whether PPP’s final Florida poll was responsible for his last-second Florida switch).
Now, while Silver laudably characterized the Florida match-up as “too close to call” in his final write-up before the election, the just slightly higher probability of an Obama victory in Florida is what allowed Silver and his allies to claim a perfect record in the 2012 presidential election. That one state also set Silver’s model apart from simple averages of state polls — including the simple average of polls include in Silver’s model, which predicted that Romney would win Florida. Getting 49 out of 50 right is what mere mortals do. But nailing 50 out of 50? That’s what made Silver a god in the pantheon of political prognostication.
For those of us who criticized Silver for having a model that basically just parroted state polls without adding much, if any, extra value, Silver’s Florida prediction was an eye-opener. Maybe he had actually cracked the code with his system of pollster ratings, momentum analysis, and state cascade factors. Maybe he had figured out how to turn polling coal into electoral diamonds.
New evidence about PPP’s methodology, or lack thereof, however, casts a shadow of doubt over the system that produced Silver’s perfect 2012 forecast. Did PPP, from the ground up and using statistically sound and reproducible polling methods, peg the accurate Florida victor, or did Jensen pick an outcome and then adjust demographic weights until the outcome he wanted was dialed in? Did he guess the final demographic breakdowns and just luck into having the right final outcome? Or was he advised by data-hungry mammoths like the Obama polling operation that the demographics would turn out a certain way and therefore he should use those weights in his final polls?
The in-depth analysis of Jensen’s work by TNR’s Cohn doesn’t tell us which , if any, of those answers is correct. But it does tell us which explanation is the most unlikely: that Jensen called up voters, recorded their responses, followed industry-accepted statistical and demographic weighting practices, and ended up with his finger precisely on the pulse of the electorate.
Silver and Jensen’s Nasty Public Break-Up
The seeming co-dependence between Jensen and Silver — Silver needed PPP’s numbers to nail Florida and Jensen needed Silver’s pollster seal of approval — is made all the more fascinating by the reactions of the two men during last week’s dust-up over Jensen’s polling techniques. Silver, in particular, used his Twitter account to rip PPP to shreds following the Colorado recall debacle and the publishing of the TNR story. Rather than paraphrasing his complaints, I’ve embedded several of his more pointed critiques below.
The main problem with @ppppolls is that their approach to polling is extremely ad hoc. (1/5)
— Nate Silver (@NateSilver538) September 12, 2013
Ultimately, that ad-hockery stems from a lack of appreciation/understanding for the statistical fundamentals behind polling. (2/5)
— Nate Silver (@NateSilver538) September 12, 2013
.@ppppolls proudly endorse the idea of using of "gut feeling" in conducting their polls. http://t.co/eAwh2sglcc (3/5)
— Nate Silver (@NateSilver538) September 12, 2013
But "gut feeling" is often used to excuse all sorts of conscious and unconscious biases. (4/5)
— Nate Silver (@NateSilver538) September 12, 2013
Statistical methods certainly do require *judgment*. But good judgment is based on evaluating PROCESS… not RESULTS. (5/5)
— Nate Silver (@NateSilver538) September 12, 2013
.@justinwolfers: One can certainly defend @ppppolls as being good FORECASTERS. But what they're doing barely qualifies as POLLING, if at all
— Nate Silver (@NateSilver538) September 13, 2013
Silver’s criticism boils down to the kind many of us received from elementary or high school math teachers: “Show your work. Your answer doesn’t count, even if it’s correct, unless you can demonstrate how you came up with it.” Silver’s final point is especially salient. Whatever it is that PPP is doing isn’t polling and it isn’t science. At best, it’s ad hoc forecasting. At worst, it’s manipulative wish-casting meant to drive a media narrative that’s either beneficial to PPP’s clients or sympathetic to the views of its directors.
Now, that may very well be what PPP’s clients want out of the firm: weaponized polls meant to change the media conversation about a particular candidate or cause. But just as pollsters who are paid by political candidates will never be able to demand the same level of credibility granted to independent analysts, PPP can’t be trusted to provide transparent, statistically defensible data, especially as long as it refuses to be honest about the game it’s playing.
Jensen fired multiple volleys back in Silver’s direction, including a deleted tweet in which he attacked Silver for asking in 2012 to have access to PPP’s polling data before it was publicly released. He later begged for a truce that appears to have been rejected by Silver.
What neither man seems to realize is how closely their credibility is tied together, and how little it behooves either individual to cut down the other. Prior to last week’s spat, Jensen could claim to be one of the most highly rated pollsters according to the great Nate Silver. And Silver could claim a unique ability to take simple poll data and turn it into a perfect oracle of election results. The consequence of last week’s brouhaha, though, is that the credibility of both is, or at least should be, significantly diminished.
Nate Silver most likely wouldn’t have gotten Florida right had Jensen not perfectly baked those final numbers according to whatever arbitrary recipe popped into his head that morning. And Jensen wouldn’t have had nearly as much polling gravitas were it not for the Silver seal of approval, represented by the disproportional weights given to PPP polls in Silver’s model.
And yet, in spite of all that, they chose to air each other’s dirty laundry and turn a simple argument over methodology into an insult-fueled public feud. A feud which only serves to make each man seem smaller and less impressive.
Politics may make strange bedfellows, but it makes even stranger enemies.










{kind=link}